Introduction
In the pre-computer era, the creation of language corpora – compilations of millions of words drawn from multiple sources – was a painstaking and laborious undertaking. Imagine researchers huddled over desks, painstakingly copying words from hundreds of texts onto index cards, and filed away into physical organizing systems.

Remember these?
Even with early computers and scanners, sampling and preparing a corpus was a time-consuming effort, and as a result, corpora were quite small. However, with the increasing accessibility of computers, improvements in natural language processing (NLP), and the massive amounts of freely available text available on the web today, all that is required to compile a corpus is a little bit of programmatic knowledge, and perhaps a large enough hard drive!
In this post, I will illustrate how the NLP process of Web Scraping can be used to mine large amounts of text from the web for use in the initial steps of creating a corpus!
Because a primary interest of mine is academic oral communication, I will be applying this process to the compilation of an (albeit limited) corpus of academic spoken English based on lectures provided by MIT OpenCourseware (https://ocw.mit.edu/index.htm).
Conceptual Overview
Conceptually, scraping text involves two key steps:
- Understanding the programmatic architecture of the website in terms of HTML tags.
- Writing a script based on these tags to extract the desired text.
To scrape data from the MIT Open Courseware website I needed to first understand its architecture, both from a user-side and a developer-side. From a user side, I immediately noticed that the actual data to scrape (video captions/transcripts already provided by the university) was nested within several different URLs. Specifically, I had to navigate to a page listing all courses containing captioned video lectures, and from there, navigate through the following: Course overview/Captions & Transcripts/Lecture/Transcript – four separate URL lists. The following pictures illustrate this.
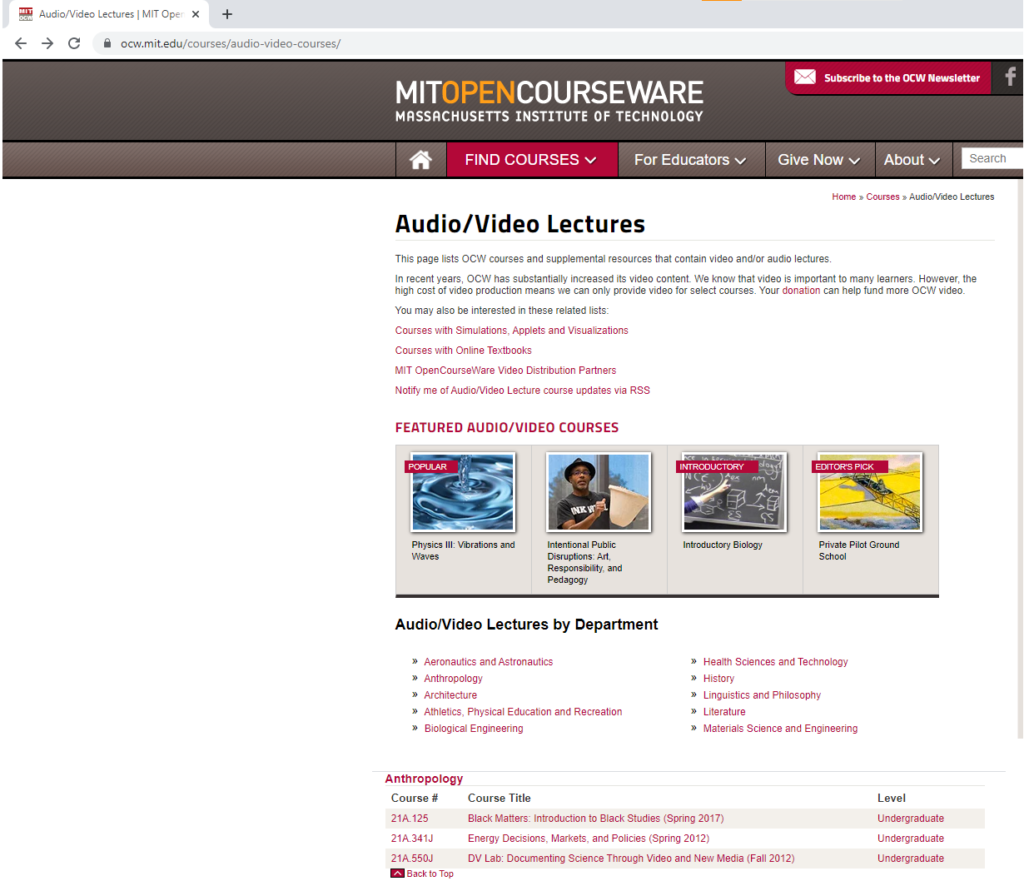
Audio/Video Lecture Home Page + Courses

Course homepage with “captions/transcript” link

List of lectures within course -> Individual lecture page
As I examined the HTML codes of several sample courses, I noticed that the architecture was more or less the same and that I could write one program to collect the URLs I need in order to go through each of them and navigate to the page where the transcript lay. There, I simply needed to locate the tag/tags under which the text I was trying to scrape lay, and write a program to extract it.
For example, on the home page for the audio/video courses (https://ocw.mit.edu/courses/audio-video-courses/), URLs to individual courses are located with <h4> tags:
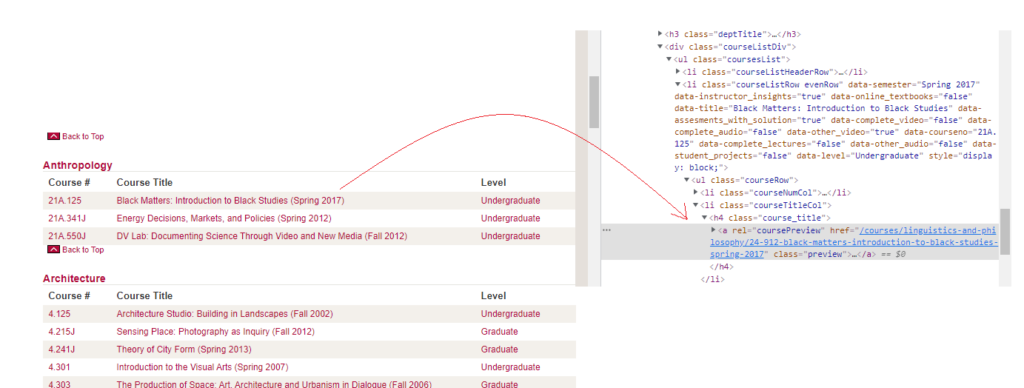
Once arriving at this page, all I needed to do was extract the already-provided transcript and save it to a text file.
Let’s look at how I did this.
Programmatic Overview
Step 1: Import necessary packages and define essential function
For this project, I used Python 3, nltk, and the BeautifulSoup package, an HTML/XML parser (https://pypi.org/project/beautifulsoup4/)
|
1 2 3 4 5 6 7 8 9 10 |
from urllib.request import urlopen #ability to open URLs from bs4 import BeautifulSoup as bs #import web scraping tool in a shorter name import os import nltk #For tokenizing import time import re from string import punctuation punct = set(punctuation) import glob from collections import Counter |
I also needed to write a function which would add the hyperlink text (i.e.,”https://ocw.mit.edu”) to all links:
|
1 2 3 4 5 |
#Defines a function to add "https:..." to all links. Two lists will be required for each step def ocw(url_list, url_list2): for x in url_list:#For each link in url_list x = 'https://ocw.mit.edu' + x #Define the link text as 'https://ocw.mit.edu' + the link url_list2.append(x)#Append to the second list |
Step 2: Create a list of relevant URLs
I started by locating the relevant HTML tags surrounding the links I needed, and creating and extracting URLs from an HREF based on the text contained in the tag.
|
1 2 3 4 5 6 7 8 9 10 11 |
#Step 1: Create a list of caption-available course URLs from the main page main_url = 'https://ocw.mit.edu/courses/audio-video-courses/'#Sets base url main_page =urlopen(main_url)#Opens the url main_soup = bs(main_page, 'html.parser')#Parses the url with beautiful soup short_url_list = []#Defines List 1 main_url_list=[]#Defines List 2, our main list of final URLs for tag in main_soup.find_all('h4'):#For each h4 tag... for x in tag.find_all('a'):#For each a tag within all h4 tags if x.get('class') == ['preview']:#If the "a" class is preview short_url_list.append(x['href'])#append the href to List 1 ocw(short_url_list, main_url_list)#Add the required https://... to the link |
This code produces a list of URLs that looks something like this:
|
1 2 3 4 5 6 |
Output: ['https://ocw.mit.edu/courses/aeronautics-and-astronautics/16-01-unified-engineering-i-ii-iii-iv-fall-2005-spring-2006', 'https://ocw.mit.edu/courses/aeronautics-and-astronautics/16-01-unified-engineering-i-ii-iii-iv-fall-2005-spring-2006', 'https://ocw.mit.edu/courses/aeronautics-and-astronautics/16-01-unified-engineering-i-ii-iii-iv-fall-2005-spring-2006', 'https://ocw.mit.edu/courses/aeronautics-and-astronautics/16-01-unified-engineering-i-ii-iii-iv-fall-2005-spring-2006', 'https://ocw.mit.edu/courses/aeronautics-and-astronautics/16-660j-introduction-to-lean-six-sigma-methods-january-iap-2012'...] |
Continuing with the pattern, I was able to create a list of URLs for pages where the video captions could be found:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
#Step 2a: Get to Videos/Captions Page for each course url_captionlist_short=[]#list 1 url_captionlist_final=[]#list 2 for link in main_url_list: time.sleep(.1)#I was worried this would take a lot more time so I added time.sleep to avoid crashing the website open_url = urlopen(link) #Opens each url in the list soup = bs(open_url, 'html.parser')#Parses each using beautiful soup for tag in soup.find_all('div', {"id": "description"}):#Iterates through tags with the relevant tag for x in tag.find_all('ul', {'class':'specialfeatures'}):#Iterates through tags with the relevant class for y in x.find_all('a'):#Iterates through <a> tags if y.text == 'Captions/transcript': appends the href to the list if it says "Captions/transcript" url_captionlist_short.append(y['href'])#adds to list 1 ocw(url_captionlist_short, url_captionlist_final) #Step 2b: For each course, make a list of individual lecture video links available for that course caption_url = list(set(url_captionlist_final))#Eliminates duplicates using "set" url_videolist_short = [] url_videolist_final = [] for link in caption_url: url_intermediate = [] time.sleep(.1) try: open_url = urlopen(link) except: #If there are any problems with URL open, just skip them pass soup = bs(open_url, 'html.parser') for tag in soup.find_all('a', {'class':'bullet medialink'}):#Iterates through tags with the class containing the href relevant to the next list url_intermediate.append(tag['href']) ocw(url_intermediate, url_videolist_final) |
Step 3
Now that I had a list of all URLs for courses with audio/video lectures that were actually accompanied by a transcript, I could scrape the text of each. Each transcript for all of the video lectures had the same format: a 3-5 tab widget which contained information about the video, a playlist, transcript, download link, and some related content. The problem, however, was that the div tag corresponding to each tag had an id that did not actually correspond to the information contained within. For example, the “Transcript” above was under the <div id=”vid_playlist”> tag and class; obviously, vid_playlist is not what it was supposed to be – vid_transcript:
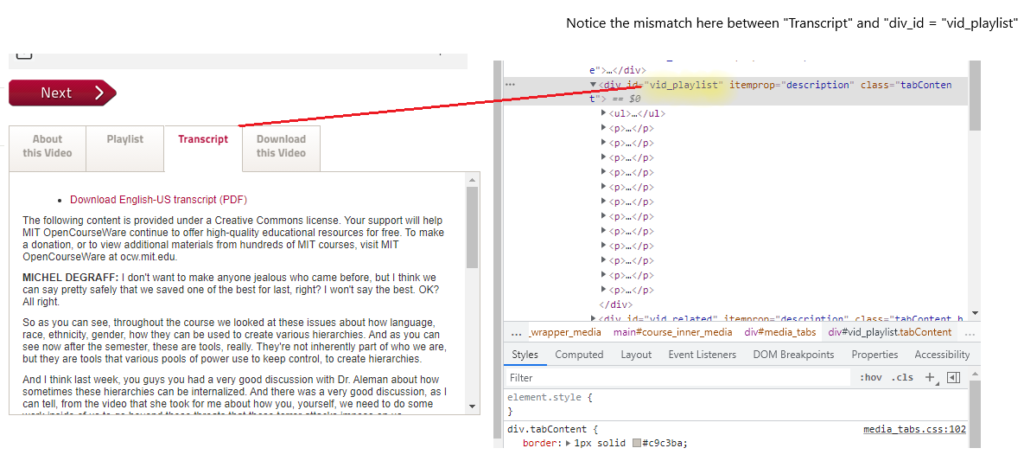
I did some digging and noticed that there were 4 tag ids (about, playlist, index, related), meaning that there could be a number of mismatch errors! However, I also noticed that for every video, the “Transcript” tab began with the word “Download”. As a quick fix, I simply wrote a program to only take text from the tag whose first 8 characters were “Download” (e.g., “Download English-US transcript (PDF)” in the image above) and the problem was solved.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
#Step 4: We need to iterate through all the individual video lecture links and pull out the transcripts from them iterator = 0 #Defines iterator for saving filenames that will have increasing numbers attached to their stems url_final = list(set(url_videolist_final))#eliminates any duplicates using set for link in url_final: meta_list = []#Defines several empty lists for later use span_list = [] meta_data = [] text_list = [] time.sleep(.1) open_url = urlopen(link) soup = bs(open_url, 'html.parser') md_box = soup.find('div', attrs={'id': 'left'}) for tag in md_box.find_all('a'): text = tag.text.strip() meta_list.append(text) for x in meta_list[2:4]: meta_data.append(x) course_name = md_box.find('span').text.strip() try: transcript_box = soup.find('div', attrs={'id': 'vid_index'})#For these pages, there was a widget box with 5 tabs, which each had ids listed below. Unfortunately, the actual transcripts were not always properly listed under the same id, so I iterated through all of them to only append text starting with the word "Download" to the list. "Download" was the consistent first word across every transcript (As in "Download English-US Transcript". transcript = transcript_box.text.strip()#Text is defined as whatever is in the widget tab with the id "vid_index" if transcript[:8] == "Download": #If the first 8 characters of that text = download... text_list.append(transcript)#Then this is the transcript, and append it to the text list else: transcript_box2 = soup.find('div', attrs={'id': 'vid_playlist'})#If playlist has Download... transcript2 = transcript_box2.text.strip() if transcript2[:8] == "Download": text_list.append(transcript2) else: transcript_box3 = soup.find('div', attrs={'id': 'vid_about'})#If about has Download... transcript3 = transcript_box3.text.strip() if transcript3[:8] == "Download": text_list.append(transcript3) else: transcript_box4 = soup.find('div', attrs={'id': 'vid_related'})#If related has Download... transcript4 = transcript_box4.text.strip() if transcript4[:8] == "Download": text_list.append(transcript4) else: transcript_box5 = soup.find('div', attrs={'id': 'vid_transcript'})#If transcript has Download... transcript5 = transcript_box5.text.strip() if transcript5[:8] == "Download": text_list.append(transcript5) else: continue except: pass #If there are any problems opening any of the URL pages, this will skip them..which is a cheap fix out_meta = "/".join(meta_data) out_string = "\n".join(text_list)#turn list into a text with words separated by newline chars filename = "Scraping Output/" + "lecture" + str(iterator) + ".txt" #make a simple filename in the working directory? outf = open(filename,"w", encoding = 'utf-8') #create outfile outf.write("Course & Lecture: " + out_meta + " - " + course_name + '\n' + 'Link: ' + link +'\n' + out_string) #write string to file outf.flush() #flush buffer outf.close() #close file iterator += |