Do Disney villains really use more sophisticated language than the heroes?
Who among us hasn’t noticed that the villains of popular Disney films tend to carry themselves with a certain air of superiority? This is certainly not a new observation. It is a known fact that villains in these animated films tend, more than not to adopt British English accents.
In fact, this trend seems to be characteristic of animated villains on the whole – at least according to one 1998 study by sociolinguists Julia Dobrow and Calvin Gidney. In their analysis of the personality traits and speech patterns of 323 characters across 76 animated children’s television shows, they found that dialect stereotypes were frequently used to indicate a character’s status as a hero or a villain. Most commonly, this meant a British English accent and hyper exaggerated features (e.g., excessively rolled “r’s”). A 2019 master’s thesis by Dea Maržić at the University of Rijeka took the analysis a step further. Maržić performed discourse analysis on nine Disney films produced between 1989 to 1998 (the so-called “Golden Age” of Disney films) to examine the ways in which Disney villains created a villainous identity. The study found, unsurprisingly, that villains tended to adopt non-American accents. However, Maržić also showed that villains tended to adopt a dual nature, presenting themselves at once as benevolent victims and authoritative dictators (think Frollo’s seemingly generous yet domineering adoption of Quasimodo in “The Hunchback of Notre Dame”).

Being a Disney aficionado myself, I wanted to know whether the superiority projected by Disney villains was also reflected at a fine-grained linguistic level. Specifically, and looking for an excuse to apply my knowledge and experience with Natural Language Processing (NLP), I was interested in knowing whether Disney villains use language that is more sophisticated than that of the heroes.
Approaching the Problem
Answering this question necessitated a number of preliminary steps.
First and foremost, what do I mean when I say “sophisticated language”? I chose to measure sophistication at the lexical (i.e., word) level, and thus adopted the index most commonly used by us vocabulary researchers: word frequency. Briefly, word frequency is determined in reference to language corpora – large-scale, structured collections of texts suitable for linguistic analysis. It involves counting the number of times a given word form (e.g., make, makes, making) or lemma (i.e., the base for of a word – make) occurs within the text, and (usually) norming the frequency count to determine how many times that word form/lemma occurs per million words. Word frequency is an appropriate way to determine the sophistication of speech since it is known to strongly correlate with multiple aspects of language growth and proficiency. For example, it is known that children acquire more frequent words earlier in their first language (e.g., Dascalu et al., 2016; Landauer, Kireyev, & Panaccione 2011); that frequent words are accessed more quickly (Brysbaert & New, 2009); and that measures of single and multi-word frequency correlate with second language proficiency (Crossley et al., 2010).
The frequency list I had on hand for this project was the Contemporary Corpus of American English Magazine sub-corpus, which consists of 127,352,030 word forms from 86,292 different texts. I was interested in analyzing the following:
- Overall type (number of unique words) and token (number of total word forms) frequency
- Most common two-word (i.e., bigram) and three-word (i.e., trigram) phrasal (i.e., part-of-speech) patterns.
- Average type and token frequency within the most common phrasal patterns.
Second, I had to determine which Disney heroes and villains I would compare. For this post, I will be reporting on an NLP case study of Jafar and Aladdin from the Disney film “Aladdin”. Analysis of other Disney villains and heroes will be reported in upcoming posts!
Third, the following was my conceptual approach to addressing this question:
- Importing and isolating the dialogue of the Jafar and Aladdin.
- Cleaning the text to remove punctuation and stopwords
- Tokenizing the lines of each character
- POS tagging the lines
- Identifying most common phrasal patterns
- Calculating word frequency
Finally, I needed a number of Python-3 packages to analyze the data according to the following standard pattern of text analysis:
- Text preprocessing (using “re”)
- Tokenization (Natural Language Toolkit [NLTK])
- POS-tagging (StanfordPOSTagger)
- Frequency counts (NLTK)
Let’s look at how I did this!
The Procedure
Let’s start by importing the necessary packages, importing the Aladdin script, and tokenizing the script.
|
1 2 3 4 5 6 |
import os #For loading text files from the hard drive import nltk #Natural Language Toolkit import re #Regular expressions for searching through text path = r'...Villians Project\aladdin.txt' a_text = open(path, 'r', encoding = 'utf-8').read()#Reads the Aladdin script a_tokenized = nltk.word_tokenize(a_text) #Tokenizes the entire script using NLTK |
We can see by looking at the script that there are three main types of text: character names, dialogue, and scene descriptions:

You may have noticed that in this script that the character names are printed in all capital letters and the scene descriptions are enclosed within parentheses. I thus wrote two quick functions to cut out anything between parentheses, and add the remaining text to a separate “dialogue” list:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
#This function is the first step in separating the dialogue from the scene descriptions. #Essentially, it iterates through a tokenized list of words until parentheses are found, then skips over them until the next character begins speaking. def c_split(tokenized, empty_list): for item in tokenized: found_c = False #Sets the "found capital letter" variable to False current = []#Defines a placeholder list length = len(item) #Sets length of list counter = 0 #Sets counter to be used with "length" to determine if an item is the last item in the list for x in item: counter +=1 if found_c == False: #If a capital letter has not been found... if re.search('[A-Z][A-Z]', x): #...and this item has two capital letters at the beginning current.append(x)#Append to placeholder list else: current.append(x) #...and this item does not have two capital letters found_c = True #Sets the variable to "capital letter found" elif found_c == True: #If a capital letter has been found if re.search(r'[A-Z][A-Z]', x): #...and this is another capital letter... found_c = False #Set the variable back to False, indicating that this is a new character talking empty_list.append(current) #Appends current list to "dialogue" (containing previous character's dialogue) current = []#Refines the placeholder list to take a new character's dialogue current.append(x) else: current.append(x) if counter == length: empty_list.append(current) #This function supplements the previous one, and takes care of scene descriptions within a character's dialogue. for i in range(len(dialogue)): if i < len(dialogue): first_item =dialogue[i][0] if re.search(r'[A-Z][A-Z]', first_item): continue else: dialogue[i]=dialogue[i-1]+dialogue[i] del dialogue[i-1] for i in range(len(dialogue)): if i < len(dialogue): first_item =dialogue[i][0] if re.search(r'[A-Z][A-Z]', first_item): continue else: dialogue[i]=dialogue[i-1]+dialogue[i] del dialogue[i-1] |
Running these two functions on our dialogue file resulted in a list of tokenized words without scene descriptions, going from this:

To this:
|
1 2 3 4 5 6 |
['ALADDIN', ':', 'All', 'this', 'for', 'a', 'loaf', 'of', 'bread', '?'], ['GUARD', '1', ':', 'There', 'he', 'is', '!'], ['GUARD', '2', ':', 'You', 'wo', "n't", 'get', 'away', 'so', 'easy', '!'], ['ALADDIN', ':', 'You', 'think', 'that', 'was', 'easy', '?'], ['GUARD', '1', ':', 'You', 'two', ',', 'over', 'that', 'way', ',', 'and', 'you', ',', 'with', 'me', '.', "We'll", 'find', 'him', '.'], |
The next step was to isolate only Jafar and Aladdin’s lines. I did this simply using the “sent_tokenize” module from NLTK, which transforms text into a list of sentences by using common punctuation as a reference:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
jafar_dialogue_split = [] for item in jafar_dialogue: current = [] for y in item: if re.search(r'JAFAR', y): continue if re.search('[^A-Za-z!\.\'?]+', y):#removes all punctuation but periods, question marks, and apostrophes (needed for contractions) continue else: current.append(y) split = nltk.sent_tokenize(" ".join(current))#split sentences based on sentence-final punctuation for x in split: current1 = [] current1.append(nltk.word_tokenize(x)) jafar_dialogue_split.append(current1) #Now we can safely remove all punctuation! jafar_dialogue_final = [] for item in jafar_dialogue_split: for y in item: current = [] for z in y: if re.search('[^A-Za-z\']+', z): continue else: current.append(z.lower()) jafar_dialogue_final.append(current)#success! |
The end result of this code was a list of Jafar’s tokenized lines without his name or needless punctuation:
|
1 2 3 4 |
[['you', 'are', 'late'], ['you', 'have', 'it', 'then'], ['you', "'ll", 'get', 'what', "'s", 'coming', 'to', 'you'], ['quickly', 'follow', 'the', 'trail']...] |
After doing the same thing for Aladdin, the next step was to remove stopwords (e.g., words that serve a grammatical function but don’t tell us much else about the content of speech; e.g., “the”, “be”) and calculate the overall frequency of each character’s words. After combining a custom stoplist (containing words that could skew sophistication like character names – e.g., “Sultan”, “Genie”) with the stoplist from NLTK, and lemmatizing each character’s lines, I built a frequency dictionary for each character and compared it to the COCA magazine word frequency lists:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
#Let's define a few functions that will help us lemmatize the text #Let's lemmatize Jafar and Aladdin's lines and remove stopwords import nltk, re from nltk.corpus import wordnet from nltk.corpus import stopwords from nltk.tokenize import word_tokenize from nltk.stem import WordNetLemmatizer from collections import Counter stop_words = stopwords.words('english') normalizer = WordNetLemmatizer() def get_part_of_speech(word): probable_part_of_speech = wordnet.synsets(word) pos_counts = Counter() pos_counts["n"] = len( [ item for item in probable_part_of_speech if item.pos()=="n"] ) pos_counts["v"] = len( [ item for item in probable_part_of_speech if item.pos()=="v"] ) pos_counts["a"] = len( [ item for item in probable_part_of_speech if item.pos()=="a"] ) pos_counts["r"] = len( [ item for item in probable_part_of_speech if item.pos()=="r"] ) most_likely_part_of_speech = pos_counts.most_common(1)[0][0] return most_likely_part_of_speech def preprocess_text(text): cleaned = re.sub(r'\W+', ' ', text).lower() tokenized = word_tokenize(cleaned) normalized = [normalizer.lemmatize(token, get_part_of_speech(token)) for token in tokenized] filtered = [word for word in normalized if word not in stop_words] return " ".join(filtered) def preprocess_normal(text): cleaned = re.sub(r'\W+', ' ', text).lower() tokenized = word_tokenize(cleaned) normalized = " ".join([normalizer.lemmatize(token, get_part_of_speech(token)) for token in tokenized]) return normalized j_dialogue_lemmatized = [normalizer.lemmatize(y, get_part_of_speech(y)) for x in jafar_dialogue_final for y in x] a_dialogue_lemmatized = [normalizer.lemmatize(y, get_part_of_speech(y)) for x in aladdin_dialogue_final for y in x] #Let's create our reference frequency dictionary import pandas as pd df = pd.read_csv(r'C:...Villians Project\freq_input.csv') ref_freq_dict = {} ref_words = [] ref_values = [] for item in df['#word']: ref_words.append(item) for value in df['normed_freq']: ref_values.append(value) for i in range(len(ref_words)): ref_freq_dict[ref_words[i]]=ref_values[i] #Let's calculate overall frequency for Jafar and Aladdin's dialogue! j_diag_freq = {} a_diag_freq = {} j_diag_full = [] a_diag_full = [] #First append the dialogue to one giant list for each character for sen in jafar_dialogue_final: for tok in sen: j_diag_full.append(tok) for sen in aladdin_dialogue_final: for tok in sen: a_diag_full.append(tok) #Let's remove stopwords from Aladdin and Jafar's dialogue from nltk.corpus import stopwords stop_words = stopwords.words('english') custom_stop = ['sultan', 'ababwa', 'abooboo', 'genie', 'abu', 'jasmine', 'ghazeem', 'jafar','aladdin', 'agrabah', 'ali', 'al', '\'d', '\'re', '\'ll', '\'m','\'s', 'uh', 'ah', '\'ve', 'ya', 'ai', 'um', 'ca'] stop_words = stop_words + custom_stop stop_words=set(stop_words) a_full_filtered = [w for w in a_diag_full if not w.lower() in stop_words] j_full_filtered = [w for w in j_diag_full if not w.lower() in stop_words] #Then create a frequency dictionary for each character for all of the words in their dialogue for token in j_full_filtered: if token in ref_freq_dict.keys(): j_diag_freq[token]=ref_freq_dict[token] for token in a_full_filtered: if token in ref_freq_dict.keys(): a_diag_freq[token]=ref_freq_dict[token] |
With the frequencies in hand, I was able to calculate the average token and type score for each character by summing the frequencies of each word token and word type and dividing them by the total number of tokens or types.
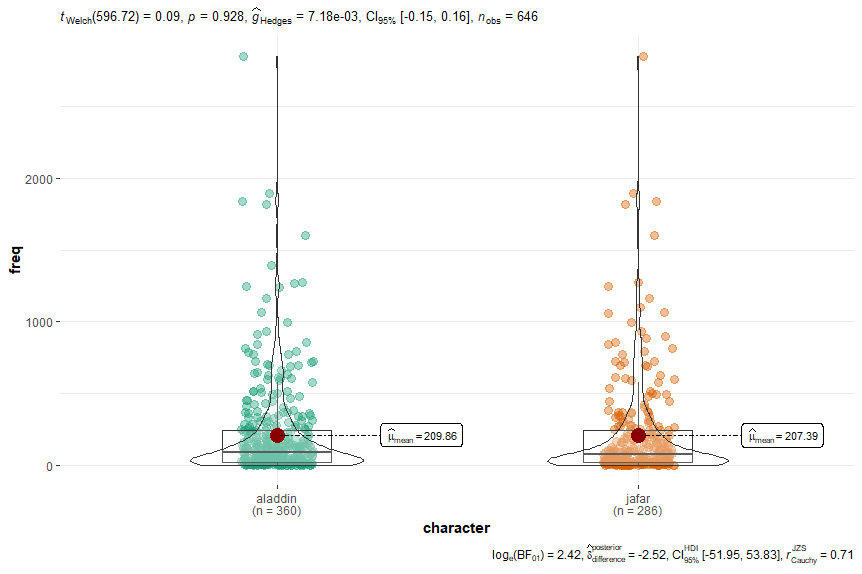
The following violin plots demonstrate the findings:
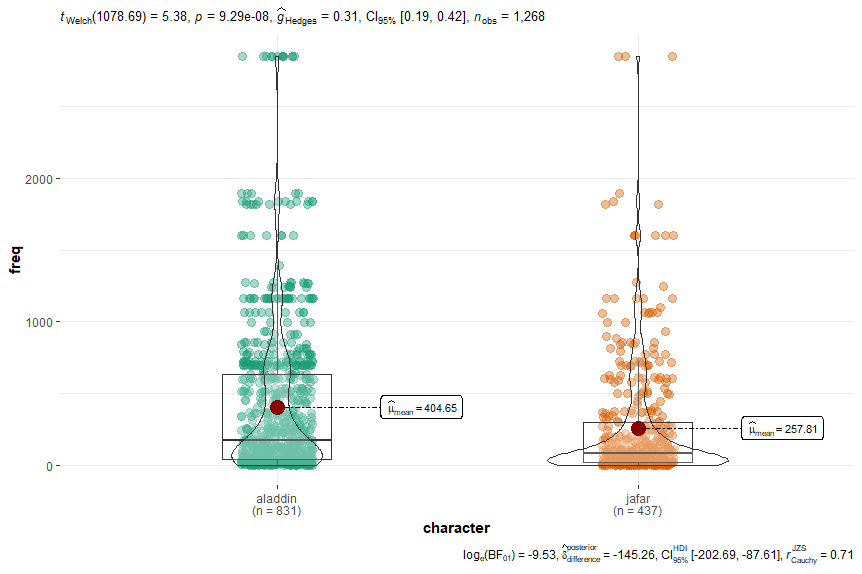
If you looked at these two plots and thought that produced opposite results, you are correct! It seems as though that in “Aladdin”, the raw number of words used by Aladdin are on average, more common than those used by Jafar. For example, Aladdin uses words like “one” (2853 / million), “like” (1837 / million), and “make” (1064 / million) multiple times in the film (seven, six, and six times, respectively). By comparison, Jafar uses these same words just once. This is not entirely surprising, considering that Aladdin has almost twice the number of lines in the film as Jafar does!
The result for type frequency is somewhat more interesting. Whereas Aladdin also uses more unique words than Jafar does (274 to 191), the average frequency of these word types does not statistically differ from Jafar’s words. For example, while Jafar snootily spits off words such as “humblest” (0.35 / million), “beheading” (0.79 / million), and “abject” (1.14 / million), Aladdin heroically counters with words like “hoofbeats” (0.12 / million), “valets” (0.33 / million), and “lawmen” (0.35 / million).
In other words, both characters seem to use an equal range of frequent and infrequent words.

So, despite projecting an obvious air of superiority, a nefarious British accent, and palpable arrogance, Jafar’s lexical performance fails to surpass that of a lowly street rat. Stay tuned for an extension of this analysis to other features of language (e.g., phrasal patterns) and other Disney characters!
Oh my God! What an impressive and interesting analysis.
At the conclusion, I would just remind the readers of the original question.
Great work!
I look forward to the next post.